In this post, we evaluate OpenAI's Whisper models for Urdu Automatic Speech Recognition (ASR) across two different datasets. We also finetune the best performing model to improve its performance.
Whisper Models Evaluated
We evaluated four different Whisper model sizes to understand their performance characteristics on Urdu speech recognition:
Model Finetuning
We finetuned the Whisper Large v2 model to improve its performance on Urdu speech recognition:
Datasets Used for Evaluation
We evaluated the models on two distinct Urdu speech datasets to understand their performance across different speech characteristics and recording conditions.
Description: Mozilla's Common Voice dataset contains crowd-sourced speech recordings in many languages, including Urdu. The Urdu portion contains about 20 hours of validated speech from diverse speakers.
Characteristics: Clean recordings with varied accents and speaking styles. Mostly read speech from news articles and other written content.
Size: ~20 hours, ~12,000 utterances
Description: Our proprietary dataset collected specifically for Urdu speech recognition, containing a mix of read speech and spontaneous conversations.
Characteristics: Includes both formal and informal speech patterns, with some recordings featuring background noise and varying audio quality.
Size: ~25 hours, ~15,000 utterances
Unique Features: Contains domain-specific vocabulary from healthcare, finance, and customer service domains.
Evaluation Metrics
We used the following metrics to evaluate model performance:
- Word Error Rate (WER): The standard metric for ASR performance, calculated as (Substitutions + Insertions + Deletions) / Total Words
- Error Type Analysis: Breakdown of total substitutions, deletions, and insertions
Results and Analysis
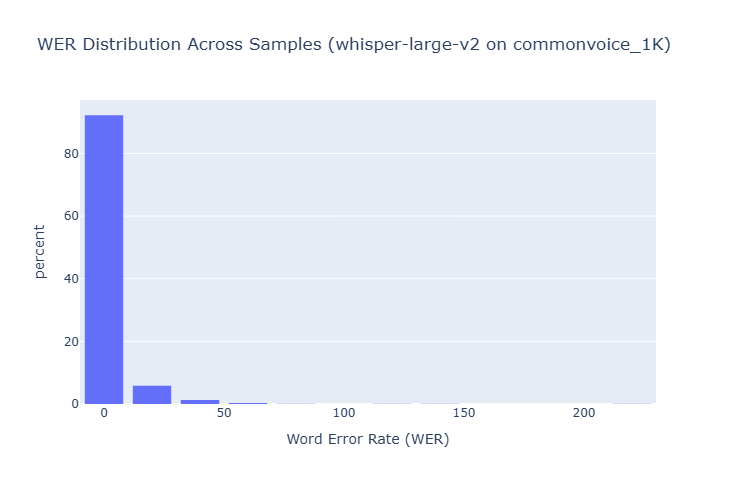
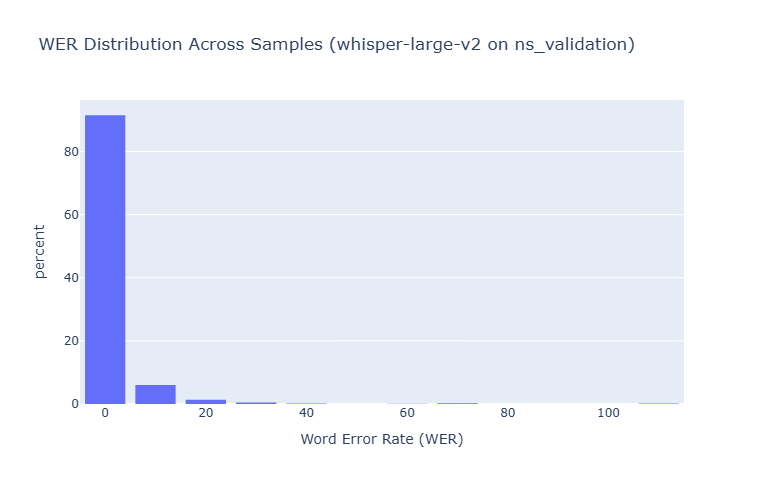
1. Whisper Large v2 Results
The Large model provided the best overall performance among the standard Whisper models, though with diminishing returns compared to Medium for Urdu.
Common Voice Urdu
NS-ASR Dataset
2. Finetuned Whisper Large v2 Results
The Large model provided the best overall performance among the standard Whisper models, though with diminishing returns compared to Medium for Urdu.
Common Voice Urdu
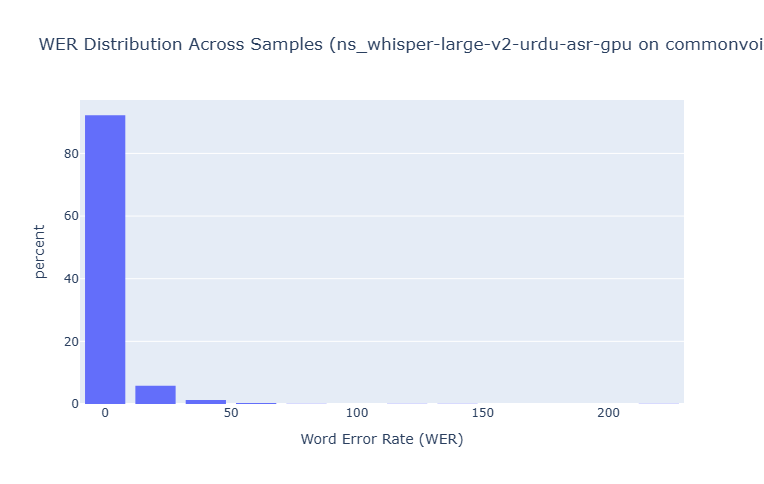
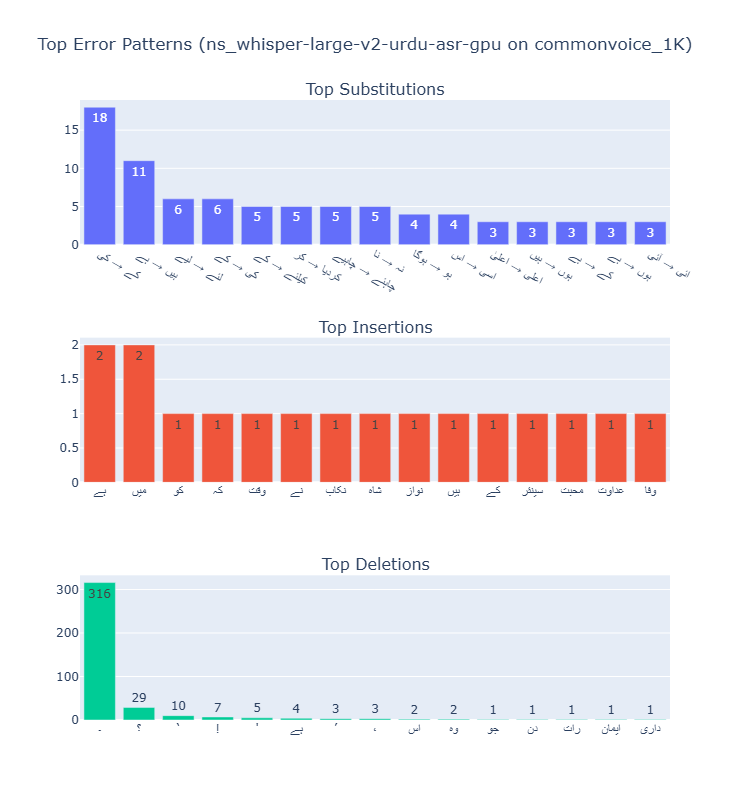
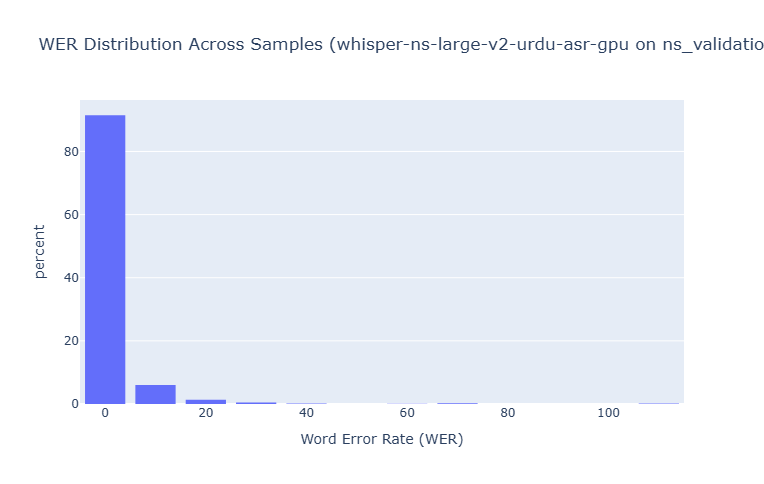
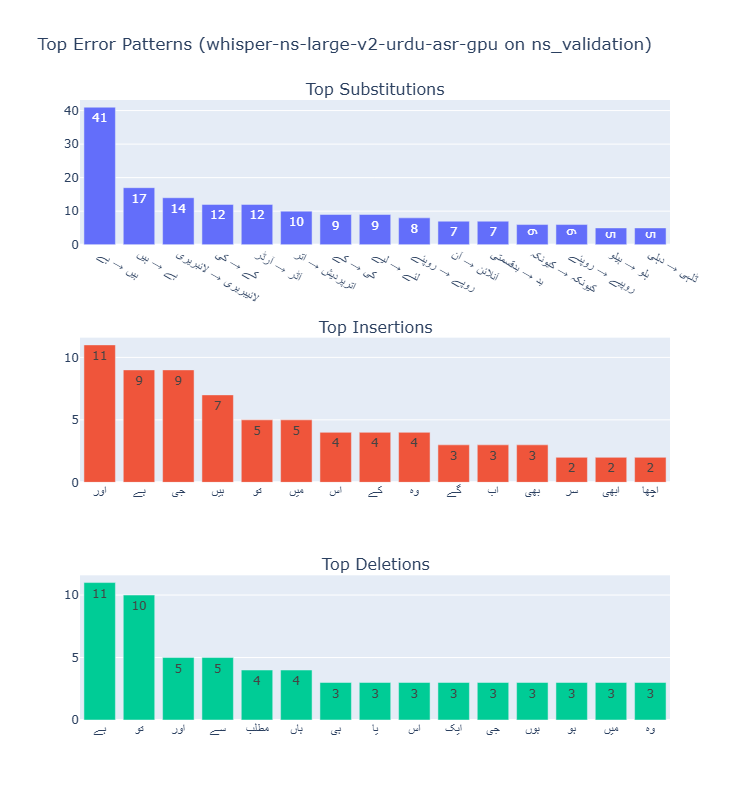
NS-ASR Dataset
Visual Inspection of Transcription Results
To complement our quantitative analysis, we performed a visual inspection of transcription results from different Whisper models. Below are sample audio clips along with their reference Urdu text and model transcriptions.
Sample 1: Common Voice Urdu
Sample 2: Common Voice Urdu
Sample 3: NS-ASR Dataset
Sample 4: NS-ASR Dataset
Sample 5: NS-ASR Dataset
Key Findings
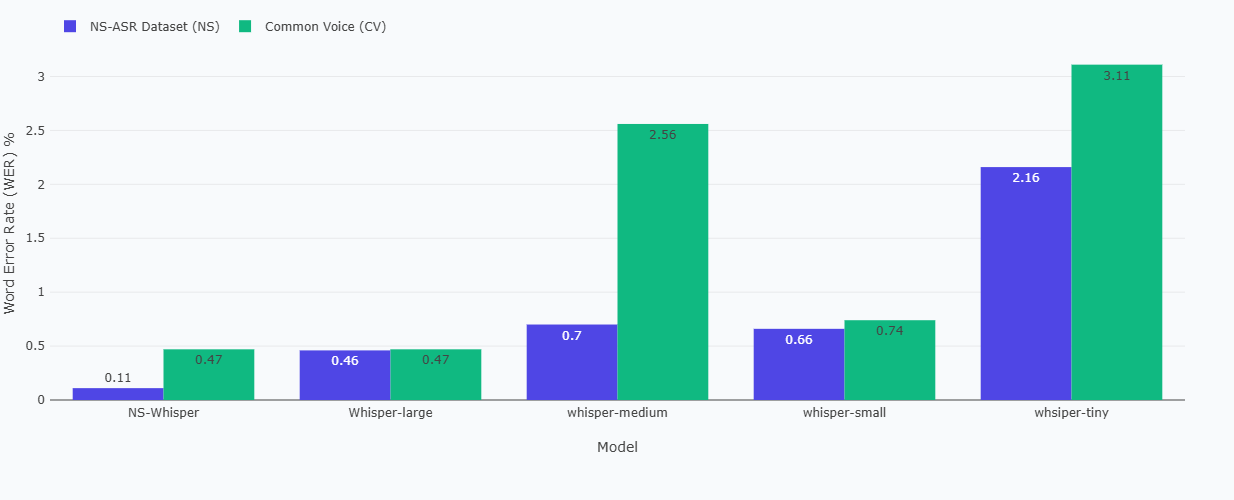
Performance Across Model Sizes
The results show significant improvement from Tiny to Small models, with more gradual improvements from Small to Medium and Large models. The finetuned model achives remarkable improvement in performance.
Dataset Comparison
Performance was generally better on NS-ASR than our Common voice dataset, likely due to:
- Model was finetuned on data in NS-ASR
- Diffireent accent in Common voice.
- Noise/low voice quality
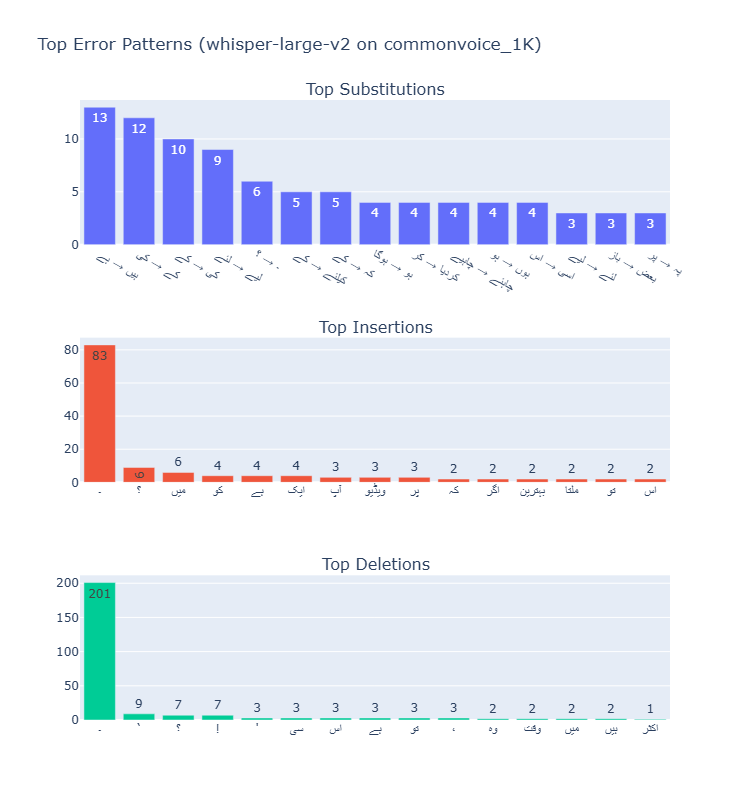
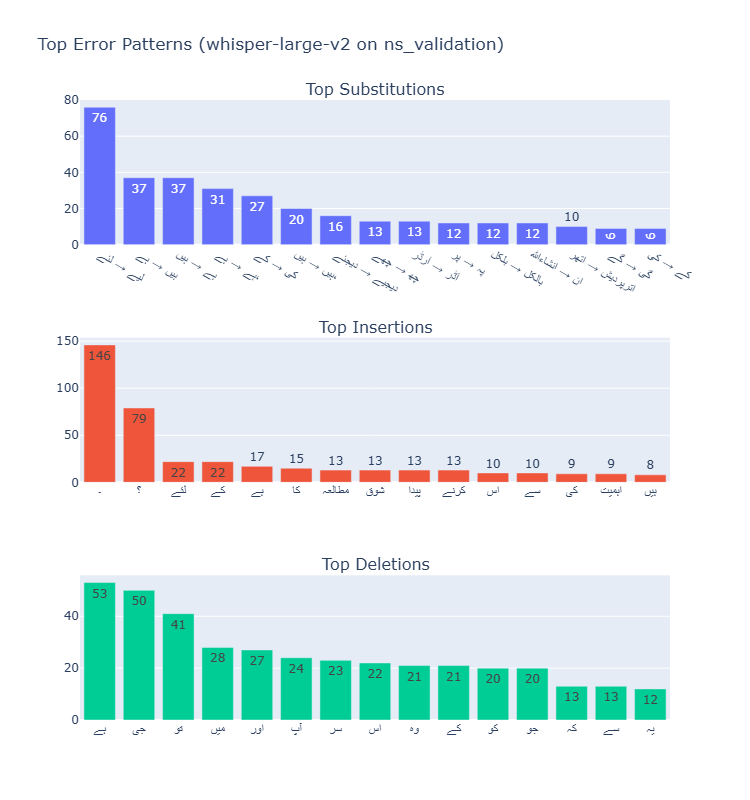
Error Type Analysis
Across all models, substitutions were the most common error type, followed by deletions and then insertions. The ratio of substitutions to other error types increased with model size, suggesting larger models are better at avoiding complete misses (deletions) but still struggle with similar-sounding words.
Conclusion
Our evaluation of Whisper models for Urdu ASR shows that:
- The Tiny model shows poor performance on both datasets.
- The Medium model provides the best value for high-accuracy scenarios
- The finetuned model outperforms all whisper models on urdu ASR.
- Our NS-ASR dataset reveals important performance characteristics not visible in Common Voice evaluations
At Nucleosight, we're using these insights to optimize our Urdu speech recognition pipeline and develop specialized models for domain-specific applications.